今回の内容
前回は、記事投稿において必要になるメタデータについて考えました。
メタデータの簡単な管理方法はCSVで管理する方法です。
今回は、このCSVを使った自動投稿を実装してみたいと思います。
今回紹介する内容を実装すれば、基本的に、そのまま運用可能です。
CSVの準備
投稿におけるメタデータを管理するためのCSVをまずは作成します。
次のような項目をCSVに作成して、それぞれ値を入力していきます。
以下は、日本語での具体例を含むテーブルです:
もちろんです!以下は指定されたカラムを持つ表の例です。3行の具体例も示しています。
| file_path | title | thumbnail_path | categories | tags | link_name | meta description | update_flag | post_id |
|---|---|---|---|---|---|---|---|---|
| /blog/md1.md | 初めての投稿 | /thumbnails/thumb1.jpg | ニュース, テクノロジー | 最新, 技術 | fist-post | これは初めての投稿です。 | True | 1 |
| /blog/md2.md | イベントのお知らせ | /thumbnails/thumb2.jpg | イベント, ビジネス | 重要, イベント | event | 今回のイベントはとても重要です。 | ||
| /blog/md3.md | 新製品のレビュー | /thumbnails/thumb3.jpg | レビュー, 製品 | 製品, 評価 | review | この新製品についてレビューします。 |
- file_path: 投稿するマークダウンのファイルのパス
- title: 投稿のタイトル
- thumbnail_path: サムネイル画像のパス
- categories: 投稿のカテゴリー。
,で区切ります。 - tags: 投稿に関連するタグ。
,で区切ります。 - link_name: 投稿のリンク名
- meta description: 投稿のメタディスクリプション(説明文)
- update_flag: 記事を更新するか Trueなら更新(一度投稿してpost_idが入力されている場合のみ有効)
- post_id: 投稿のID
post_idは投稿後の記事IDを記録する列になるので、新規投稿の場合、入力不要です。
更新フラグのupdate_flagはすでに投稿してpost_idがわかっている投稿を更新したいときに1にします。
ほかにも設定したいメタデータや逆に不要なデータについては、適宜編集してください。
このCSVをwp_post.csvなどとして保存しておきます。
投稿処理の流れ
それでは実際に投稿を行うコードを作成していきます。
基本的な処理の流れは、
- CSVファイルを読み込んで1行ずつ処理を行う
- post_idがなければ、未投稿なので、titleやlinkなど各種データ読み込む
- file_pathから記事の本文になるマークダウンを読み込む
- 読み込んだマークダウンをHTMLに変換する
- 変換の際に、記事内部の画像をアップロードする
- サムネイル画像をアップロードする
- 変換したHTMLをbodyにして、残りのメタデータも設定を行い投稿する
というのが新規投稿の基本的な流れです。
記事の更新の場合は、
post_idが損際して、かつ、update_flag==Trueの場合に、記事のデータを新規投稿と同じようにセットして、更新になります。
Google Colabを使った具体例
今回は、GoogleClabを使って、そのまま動かせるコード例を作成していきたいと思います。
コードはこちら
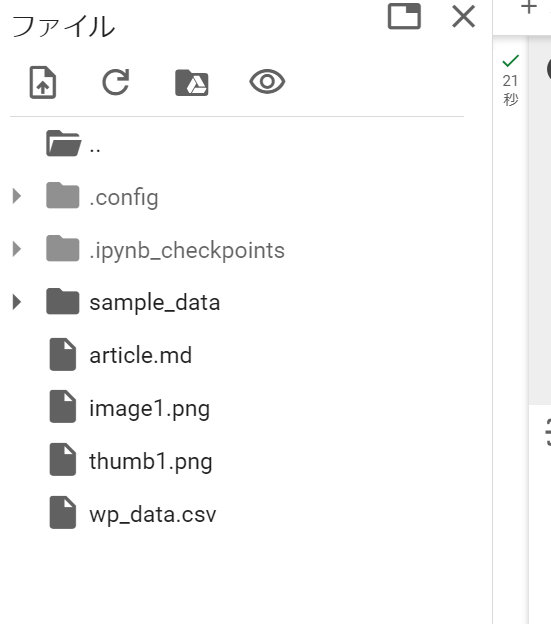
テスト用に使うCSVファイルと、マークダウンファイル、画像ファイルはそれぞれ以下です。
CSVファイル
マークダウンファイル
投稿画像
サムネイル画像
マークダウンファイルの中身は以下です。
## はじめての投稿のテスト
Pythonから投稿をしてみたいと思います。
- リスト1
- リスト2
[リンク](https://lifetechia.com/wp-autopost-from-csv/)

使用するファイルのダウンロード
まずは、今回テストで使用するデータをダウンロードしてきます。
!pip install gdown
import gdown
# CSVファイル
csv_url = 'https://drive.google.com/uc?id=1kvJesVr8amcQJDqUfbplLPwmu8i8ztAU'
gdown.download(csv_url, 'wp_data.csv', quiet=False)
# マークダウンファイル
markdown_url = 'https://drive.google.com/uc?id=1kzqvWmPak3t0e9q86SYc9E3FxmsZkGLG'
gdown.download(markdown_url, 'article.md', quiet=False)
# 投稿画像
post_image_url = 'https://drive.google.com/uc?id=1l-AQzTxbwh072_71uiJ8134zYUGN9QgK'
gdown.download(post_image_url, 'image1.png', quiet=False)
# サムネイル画像
thumbnail_image_url = 'https://drive.google.com/uc?id=1kzyte__2tmNlRgGyVT12GcD79DtfBWhY'
gdown.download(thumbnail_image_url, 'thumb1.png', quiet=False)
ここはテスト用にデータを準備しているだけなので、普通に投稿する場合には不要です。
認証情報の登録
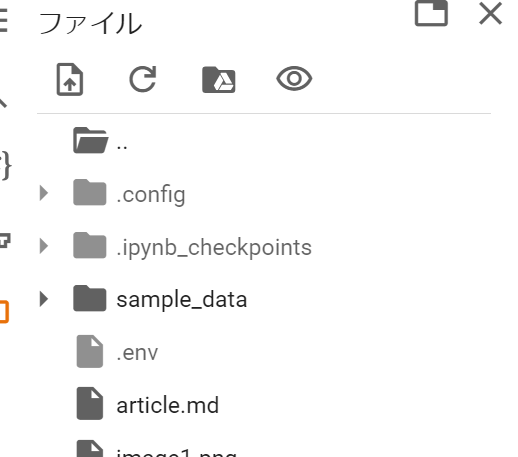
.envというファイルを作成して、以下の項目を記述します。
WordPressログインで使用するIDとパスワード、サイトのドメイン(URL)を記述してください。
この.envをGoogleColabにアップロードします。
wordpress_id = 'userid'
wordpress_pw = 'pass'
wordpress_url = 'https://○○.com'
もしよくわからない場合は、認証情報を直接手入力も可能ですので、後ほど該当部分で説明します。その場合、この部分は飛ばして問題ありません。
アップロード後、環境変数として読み込みます。
! pip install python-dotenv
from dotenv import load_dotenv
load_dotenv()
ライブラリの準備
必要なライブラリをインストールします。
wordpress_xmlrpcは一部機能で、古いライブラリを参照しているので、修正も行います。
!pip install python-wordpress-xmlrpc
! pip install python-markdown-math
import os
# base_py_path = os.path.join(os.path.dirname(wordpress_xmlrpc.__file__), 'base.py')
base_py_path = '/usr/local/lib/python3.10/dist-packages/wordpress_xmlrpc/base.py'
# base.pyファイルを修正
with open(base_py_path, 'r') as file:
data = file.read()
data = data.replace('collections.Iterable', 'collections.abc.Iterable')
with open(base_py_path, 'w') as file:
file.write(data)
print("wordpress-xmlrpcライブラリを修正しました。")
import pandas as pd
import time
from PIL import Image, ImageDraw, ImageFont
from wordpress_xmlrpc import Client
import shutil
import os
import numpy as np
import datetime
import pandas as pd
import os
import numpy as np
from datetime import datetime, timedelta
import pytz
import markdown
import httplib2
import os
import markdown
from IPython.display import HTML, display
from apiclient.discovery import build
from oauth2client import tools, file, client
import datetime
from PIL import Image, ImageDraw, ImageFont
import json
from bs4 import BeautifulSoup
from wordpress_xmlrpc import Client, WordPressPost, WordPressPage
from wordpress_xmlrpc.methods import media, posts
from wordpress_xmlrpc.methods.posts import NewPost,GetPost, EditPost
from wordpress_xmlrpc.methods.media import UploadFile,GetMediaItem
import re
import shutil
import glob
import sys
import requests
変数設定とファイル読み込み
変数を設定して、CSVファイルを読み込みます。
今回は下書き投稿にします。
post_data_path = 'wp_data.csv'
overwrite = False
status = 'draft' #"draft", "publish",'future
df = pd.read_csv(post_data_path)
df
認証情報などを設定
認証情報を設定します。
先ほどの.envがよくわからなかった場合は、こちらに直接IDやパスワードを書いてください。
# Set URL, ID, Password
wordpress_id = os.environ['wordpress_id']
wordpress_password = os.environ['wordpress_pw']
base_url = os.environ['wordpress_url']
wp = Client(base_url+'/xmlrpc.php', wordpress_id, wordpress_password)
直接記述する場合の例
wordpress_id = 'userid'
個別の投稿
まずはわかりやすいように最初の投稿だけ行ってみます。
i = 0
row = df.iloc[i,:]
row
HTMLへの変換
def convert_to_html_and_display(text, extensions=None,configs={}):
if extensions is None:
extensions = ['fenced_code', 'tables',
'abbr','attr_list','def_list','footnotes',
'admonition','nl2br','sane_lists', 'toc','mdx_math','extra'
]
if configs=={}:
configs = {
'codehilite':{
'noclasses': True
},
'toc': {
'title': '目次',
'toc_depth':3, #どの階層まで表示するか
},
# 'mdx_math': {'enable_dollar_delimiter': True}
}
html = markdown.markdown(text, extensions=extensions, extension_configs=configs)
return html
post_id = row['post_id']
if post_id == '' or post_id is None or post_id is np.nan or str(post_id) == 'nan':
with open(row['file_path'], 'r', encoding='utf-8') as file:
text = file.read()
html = convert_to_html_and_display(text)
html
画像処理
def copy_text_wp(wp,html,img_folder,upload_type=1):
# Beautiful SoupでHTMLを解析
soup = BeautifulSoup(html, 'html.parser')
media_ids = []
non_img = False
for img_tag in soup.find_all('img'):
# imgタグの親要素が<pre>または<code>タグでない場合にのみ処理を行う
if img_tag.find_parent(['pre', 'code']) is None:
if img_tag.get('src')[:4]!='http':
img_file = os.path.basename(img_tag['src'])
img_path = os.path.join(img_folder, img_file)
media_id = wp_upload_image(wp, img_path, overwrite=True,upload_type=upload_type)
if media_id is not None:
media_ids.append(media_id)
meta_data = get_media_data(wp, media_ids[-1])
sizes = meta_data['sizes']
if 'large' in sizes.keys():
new_file_name = sizes['large']['file']
else:
new_file_name = meta_data['file']
img_tag['src'] = f'{base_url}/img/' + new_file_name
img_tag['class'] = f'wp-image-{media_id}'
else:
raise ValueError
# 新しいHTMLを表示
# display(HTML(str(soup)))
if non_img:
return None
# import pyperclip
# pyperclip.copy(str(soup))
return str(soup), media_ids
def wp_upload_image(wp, img_path, out_img_name=None, overwrite=True, upload_type=1):
'''
upload_type:0 アップロードしない
upload_type:1 ファイルがない場合のみupload
upload_type 2 すべて
'''
if upload_type == 0:
media_items = wp.call(media.GetMediaLibrary({'mime_type': 'image/png'}))
for item in media_items:
if item.metadata['file'] == out_img_name:
return item.id
return None
if out_img_name is None:
out_img_name = os.path.basename(img_path)
if os.path.exists(img_path):
# 既存の同名画像を削除
if overwrite:
media_items = wp.call(media.GetMediaLibrary({'mime_type': 'image/png'}))
for item in media_items:
if item.metadata['file'] == out_img_name:
if upload_type == 2:
check = input(f'{out_img_name}はすでに存在します。上書きしますか?(y/n/p)')
if check == 'y' or check == 'Y':
wp.call(posts.DeletePost(item.id))
print(f"{out_img_name} の既存ファイルを削除しました。ID: {item.id}")
elif check == 'p':
return item.id
else:
return item.id
with open(img_path, 'rb') as f:
binary = f.read()
data = {
"name": out_img_name,
"type": 'image/png', # 画像のMIMEタイプ
"bits": binary
}
response = wp.call(media.UploadFile(data))
media_id = response['id']
print(f"{out_img_name} のアップロードに成功しました。ID: {media_id}")
return media_id
else:
print(f"{out_img_name} が見つかりません")
return None
def get_media_data(wp, media_id):
response = wp.call(GetMediaItem(media_id))
metadata = response.metadata
return metadata
html, media_ids = copy_text_wp(wp,html,"")
サムネイル画像の処理
media_id = wp_upload_image(wp, row['thumbnail_path'])
新規投稿
def post_to_wp(wp, title, body, categories=[], tags=[], status = "draft",eye_catch_img_id=None, link_name=None,meta_data=None, date=None, comment_status=False):
#publish
# Post
post = WordPressPost()
post.title = title
post.content = body
post.post_status = status
post.comment_status=comment_status
if tags == ['']:
post.terms_names = {
"category": categories,
}
else:
post.terms_names = {
"category": categories,
"post_tag": tags,
}
if meta_data:
post.custom_fields = [
{'key': 'the_page_seo_title', 'value': meta_data['title']},
{'key': 'the_page_meta_description', 'value': meta_data['description']},
{'key': 'the_page_meta_keywords', 'value': meta_data['keywords']},
]
post.slug = link_name
# Set eye-catch image
if eye_catch_img_id:
post.thumbnail = eye_catch_img_id
# Post Time
# post.date = datetime.datetime.now() - datetime.timedelta(hours=9)
if date is not None:
post.date = date
post_id =wp.call(NewPost(post))
return post_id
title = row['title']
categories = row['categories'].split(', ')
tags = row['tags'].split(', ')
meta_data = {'title':title, 'keywords':", ".join(categories + tags), 'description':row['meta description']}
link_name = row['link_name']
post_id = post_to_wp(wp, title, html, categories=categories,tags=tags, eye_catch_img_id=media_id,meta_data=meta_data,status=status, link_name=link_name)
更新の場合
更新の場合は、以下の関数を使います。
def update_wp_post(wp, post_id, title=None, body=None, categories=[], tags=[], status=None, eye_catch_img_id=None, link_name=None, meta_data=None, date=None, comment_status=None):
# Get the existing post
post = wp.call(GetPost(post_id))
# Update title if provided
if title is not None:
post.title = title
# Update body if provided
if body is not None:
post.content = body
# Update status if provided
if status is not None:
post.post_status = status
# Update comment status if provided
if comment_status is not None:
post.comment_status = comment_status
# Update categories and tags
if tags == [''] or tags == [] and categories != []:
post.terms_names = {
"category": categories,
}
elif categories != []:
post.terms_names = {
"category": categories,
"post_tag": tags,
}
# Update meta data if provided
if meta_data:
post.custom_fields = [
{'key': 'the_page_seo_title', 'value': meta_data.get('title', '')},
{'key': 'the_page_meta_description', 'value': meta_data.get('description', '')},
{'key': 'the_page_meta_keywords', 'value': meta_data.get('keywords', '')},
]
# Update link name if provided
if link_name is not None:
post.slug = link_name
# Update eye-catch image if provided
if eye_catch_img_id is not None:
post.thumbnail = eye_catch_img_id
# Update post date if provided
if date is not None:
post.date = date
# Update the post
return wp.call(EditPost(post_id, post))
すべてのデータを投稿
まとめて投稿を行うためにfor文でまとめます。(テストは1つのみです)
for i in range(len(df)):
row = df.iloc[i,:]
post_id = row['post_id']
if post_id == '' or post_id is None or post_id is np.nan or str(post_id) == 'nan' or str(row['update_post'])=='1':
with open(row['file_path'], 'r', encoding='utf-8') as file:
text = file.read()
html = convert_to_html_and_display(text)
html, media_ids = copy_text_wp(wp,html,"")
media_id = wp_upload_image(wp, row['thumbnail_path'])
if str(row['update_post'])=='1':
post_status = update_wp_post(wp, post_id, title=title, body=html, categories=categories,tags=tags, eye_catch_img_id=media_id,meta_data=meta_data,status=status, link_name=link_name)
print(f'{link_name} {post_id}を更新しました')
assert post_status==True
else:
post_id = post_to_wp(wp, title, html, categories=categories,tags=tags, eye_catch_img_id=media_id,meta_data=meta_data,status=status, link_name=link_name)
df.at[i,'post_id'] = int(post_id)
print(f'{link_name} {post_id}を投稿しました')
df.to_csv(post_data_path,index=False)
更新のテスト
最後に更新のテストを行います。
df.loc[0,'update_post'] = '1'
for i in range(len(df)):
row = df.iloc[i,:]
post_id = row['post_id']
if post_id == '' or post_id is None or post_id is np.nan or str(post_id) == 'nan' or str(row['update_post'])=='1':
with open(row['file_path'], 'r', encoding='utf-8') as file:
text = file.read()
html = '<h2>更新しました</h2>' + convert_to_html_and_display(text)
html, media_ids = copy_text_wp(wp,html,"")
media_id = wp_upload_image(wp, row['thumbnail_path'])
if str(row['update_post'])=='1':
post_status = update_wp_post(wp, int(post_id), title=title, body=html, categories=categories,tags=tags, eye_catch_img_id=media_id,meta_data=meta_data,status=status, link_name=link_name)
print(f'{link_name} {post_id}を更新しました')
assert post_status==True
else:
post_id = post_to_wp(wp, title, html, categories=categories,tags=tags, eye_catch_img_id=media_id,meta_data=meta_data,status=status, link_name=link_name)
df.at[i,'post_id'] = int(post_id)
print(f'{link_name} {post_id}を投稿しました')
df.to_csv(post_data_path,index=False)
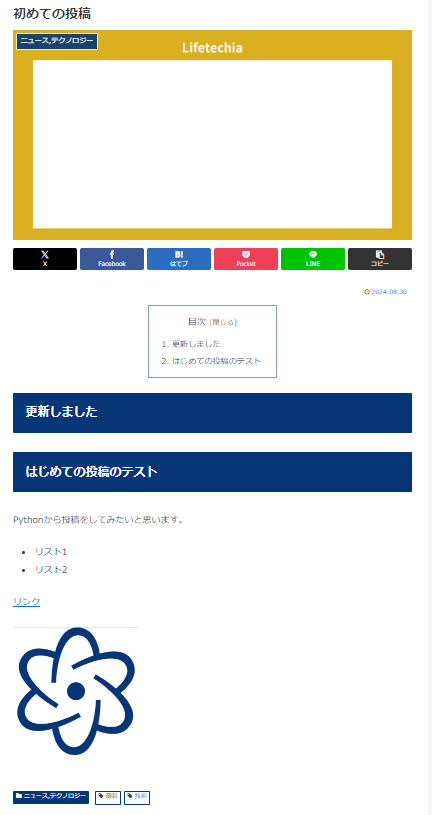
投稿の確認
画像のような投稿が確認できれば成功です。