
GPUないけど、なんとかして、CPUでChatGPTのようなAIチャットを動かしたい!
今回はその方法を紹介します。
この記事では、ローカルのCPU環境で大規模言語モデル(LLM)を動かすために、DockerとOllama、およびOpenWebUIを使用する方法を説明します。これにより、AIをローカルで簡単に活用できるようになります。
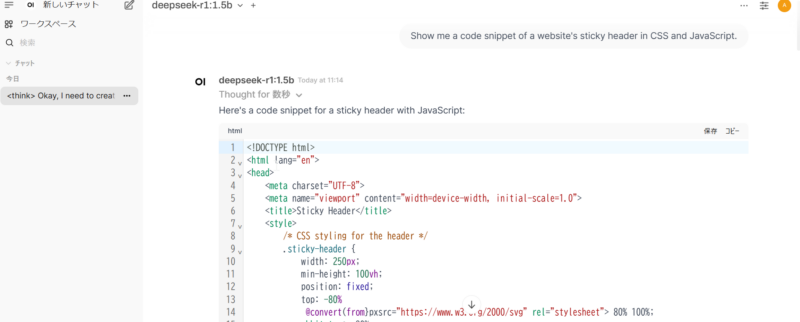
必要なもの
- Docker
手順
以下の手順に従って、ローカルのCPU上で大規模言語モデルを実行するためのDocker環境をセットアップします。
1. Docker Composeファイルの作成
まず、docker-compose.ymlという名前のファイルを作成し、以下の内容を記述します。このファイルでは、OllamaとOpenWebUIの2つのサービスを定義します。
version: '3.8'
services:
ollama:
image: ollama/ollama
container_name: ollama
restart: always
ports:
- "11434:11434" # OllamaのデフォルトのAPIポート
volumes:
- ollama_data:/root/.ollama # Ollamaのデータを永続化
openwebui:
image: ghcr.io/open-webui/open-webui:ollama
container_name: openwebui
restart: always
depends_on:
- ollama # OpenWebUIはOllamaが先に起動している必要がある
ports:
- "3000:8080" # Web UIのポート設定
volumes:
- openwebui_data:/app/backend/data # OpenWebUIのデータを永続化
volumes:
ollama_data: # Ollamaの永続化データ用ボリューム
openwebui_data: # OpenWebUIの永続化データ用ボリューム
詳細な説明
ollamaサービス:ollama/ollamaというDockerイメージを使用し、コンテナ名をollamaに設定しています。- コンテナ内でOllamaを実行し、ポート
11434をホストに公開します。 -
永続化されたデータを保存するためにボリューム
ollama_dataを使用します。 -
openwebuiサービス: ghcr.io/open-webui/open-webui:ollamaというイメージを使用し、コンテナ名をopenwebuiに設定しています。ollamaサービスが起動した後にこのサービスが起動するように、depends_onオプションを使って依存関係を指定しています。- Web UIはポート
8080を使用しており、ホストのポート3000にマッピングされています。
2. Docker Composeでサービスを起動
作成したdocker-compose.ymlファイルを使って、Docker Composeを使用してサービスを起動します。以下のコマンドを実行してください。
docker-compose up -d
- このコマンドはバックグラウンドでコンテナを起動します。
- 最初に
ollamaが起動し、その後openwebuiが起動します。
3. Ollamaにモデルをプル
ollamaが正常に起動したら、実際に好きなモデルをローカルにプルします。以下のコマンドを実行して、deepseek-r1:1.5bという言語モデルをOllamaにダウンロードします。
docker exec -it ollama ollama pull deepseek-r1:1.5b
docker exec -it ollamaコマンドは、ollamaコンテナ内でコマンドを実行するために使用します。ollama pull deepseek-r1:1.5bは指定したモデル(ここではdeepseek-r1:1.5b)をOllamaにダウンロードします。
4. OpenWebUIでモデルを操作
モデルがダウンロードされたら、ブラウザを開いてまずは、
http://localhost:11434にアクセスして、Ollamaが動いていることを確認します。
その後、http://localhost:3000にアクセスします。これで、OpenWebUIを通じてOllamaで実行しているモデルを操作することができます。
先にOllamaリンクにアクセスしないとエラーになります。
また、アクセス後も起動まで時間がかかる場合があります。
詳細は以下の記事で説明しています。

5. モデルの利用
このままではモデルが選択できない状態になっています。
以下方法でOllamaへのリンクを修正します。
まずは、左側のアイコンから設定を表示します。
続いて、管理者設定を選択します。
その後、接続を選択すると以下のようなURL設定画面になります。
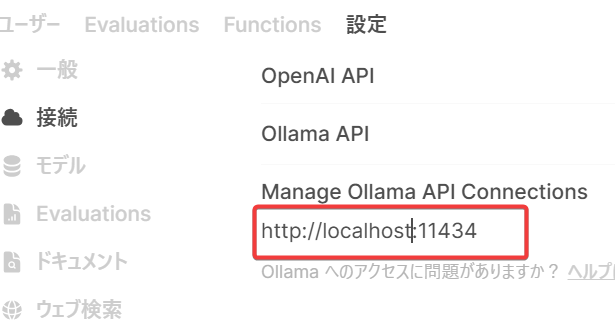
ここのOllamaURLを以下のように書き換えます。
http://host.docker.internal:11434
保存をクリックします。
これでWeb UIから、Ollamaにロードされたモデルを選択し、テキスト入力や質問を行うことで、モデルの出力を得ることができます。これにより、ローカルCPU上でAIチャットを簡単に試すことができます。
快適とはいかないですが、DeepSeekr1の1.5bであれば、普通のCPUのPCでも実行が可能でした。
まとめ
この手順に従うことで、Dockerを使ってOllamaおよびOpenWebUIをセットアップし、ローカルでLLMを簡単に動作させることができます。これにより、大規模な言語モデルを手軽にローカルで試し、実験することが可能になります。

