
🔍 はじめに
ファクター投資の世界では、**リスクのバランスをとる「リスクパリティ」**と、**過去のリターンを活かす「モメンタム」**は、それぞれ有効性が実証されたアプローチです。
本記事では、それらをファーマ=フレンチのファクターデータを用いてPythonで組み合わせ、以下のような合成戦略を4パターン実装&比較していきます。
使用する戦略(コンポーネント)
まず、ベースとなる2つの戦略は以下のように定義済みとします:
RiskParityStrategyScipy(リスクパリティ)(quantechia.strategy.riskに実装)MomentumStrategy(ファクターモメンタム)
from quantechia.strategy import risk, basestrategy
from quantechia import analysis
class MomentumStrategy(basestrategy.BaseStrategy):
def __init__(self, price_data: pd.DataFrame = None, rtn_data: pd.DataFrame = None,window=12,alpha=1, strategy_name: str = None, initial_capital: float = 1, shift_num: int = 1, cost: bool = True, cost_unit: float = 0.0005):
super().__init__(price_data, rtn_data, strategy_name, initial_capital, shift_num, cost, cost_unit)
self.window = window
self.alpha = alpha
def calculate_weight(self) -> pd.DataFrame:
# モメンタムスコア(r/r)
rolling_mean = self.rtn_data.rolling(window=self.window).mean()
rolling_std = self.rtn_data.rolling(window=max(10, self.window)).std()
rr_score = rolling_mean / (rolling_std + 1e-8)
rr_score = rr_score.clip(0, 1.5)
# 直近1ヶ月のリターンを取得
recent_return = self.rtn_data.shift(1)
# NaN行を除外してトップファクターを取得
top_factors = recent_return.dropna(how='all').idxmax(axis=1)
# 補正マスクを作成
bonus = pd.DataFrame(0, index=rr_score.index, columns=rr_score.columns)
for date, factor in top_factors.items():
if factor in bonus.columns:
bonus.at[date, factor] = 1
# 補正スコアの加算(ボーナスを加える)
adjusted_score = rr_score + self.alpha * bonus
self.score = adjusted_score
# スコアの合計が±1になるようにスケーリング
valid_score = adjusted_score.dropna(how='all')
weights = valid_score.div(valid_score.abs().sum(axis=1), axis=0)
return weights
rp = risk.RiskParityStrategyScipy(index_data)
rp.calculate_weight()
rp_w = rp.weight
mom = MomentumStrategy(index_data, window=12)
mom.calculate_weight()
mom_w = mom.weight
score = mom.score
この rp(リスク分散)と mom(勢い)をうまく活用しながら、合成戦略を実装していきます。
合成戦略のパターン(全4種類)
① スコア掛け算+正規化(MulNorm)
モメンタムスコアをそのまま重みに乗せて、合成後に正規化します。
class CombinedStrategyMulNorm(BaseStrategy):
def calculate_weight(self) -> pd.DataFrame:
rp_w = self.rp_strategy.weight
score = self.momentum_strategy.score
combined = rp_w.mul(score, axis=1)
combined = combined.div(combined.sum(axis=1), axis=0)
return combined
② 単純平均(WeightedAvg)
リスクパリティとモメンタム戦略のウェイトを0.5ずつで平均化。
class CombinedStrategyWeightedAvg(BaseStrategy):
def calculate_weight(self) -> pd.DataFrame:
rp_w = self.rp_strategy.weight
mom_w = self.momentum_strategy.weight
combined = 0.5 * rp_w + 0.5 * mom_w
combined = combined.div(combined.sum(axis=1), axis=0)
return combined
③ スコア上位Nのみ採用(TopN)
モメンタムスコア上位N個(例:3個)のファクターのみ採用してRP重みを残します。
class CombinedStrategyTopN(BaseStrategy):
def __init__(..., top_n=3, ...):
...
def calculate_weight(self) -> pd.DataFrame:
rp_w = self.rp_strategy.weight
score = self.momentum_strategy.score
mask = score.rank(axis=1, ascending=False) <= self.top_n
mask = mask.astype(float)
combined = rp_w.mul(mask, axis=1)
combined = combined.div(combined.sum(axis=1), axis=0)
return combined
④ スコア×逆ボラティリティ(ScoreVol)
モメンタムスコアと逆ボラティリティ(安定性)を掛けて重みを算出。
class CombinedStrategyScoreVol(BaseStrategy):
def calculate_weight(self) -> pd.DataFrame:
rp_w = self.rp_strategy.weight
score = self.momentum_strategy.score
vol = self.price_data.pct_change().rolling(window=21).std()
inv_vol = 1 / vol
inv_vol = inv_vol.replace([np.inf, -np.inf], 0).fillna(0)
combined = score * inv_vol
combined = combined.div(combined.sum(axis=1), axis=0)
return combined
戦略の実行と比較
データ取得
from quantechia.factor import fama_french
import pandas as pd
data = fama_french.get_ff()
del data['RF']
index_data = (1+data/100).cumprod()
index_data.index = index_data.index.to_timestamp(how='end').date
index_data.index = pd.to_datetime(index_data.index)
index_data
戦略インスタンスを生成
strategies = {
"MulNorm": CombinedStrategyMulNorm(index_data, rp, mom),
"WeightedAvg": CombinedStrategyWeightedAvg(index_data, rp, mom),
"TopN": CombinedStrategyTopN(index_data, rp, mom, top_n=3),
"ScoreVol": CombinedStrategyScoreVol(index_data, rp, mom),
}
各戦略のパフォーマンスを評価
results = []
for name, strat in strategies.items():
stat = strat.evaluate()
stat["strategy"] = name
results.append(stat)
performance_df = pd.DataFrame(results).set_index("strategy")
performance_df
📈 表として比較できるようになります。
(例:CAGR、シャープレシオ、最大ドローダウン、勝率など)
合成戦略のパフォーマンス比較・考察
| strategy | Sharpe Ratio | Max Drawdown | Winning Rate | Turnover |
|---|---|---|---|---|
| MulNorm | 2.66 | -19.35% | 59.9% | 70.1% |
| WeightedAvg | 3.45 | -14.30% | 61.5% | 38.8% |
| TopN | 3.79 | -11.97% | 60.1% | 42.4% |
| ScoreVol | 2.81 | -17.47% | 59.5% | 75.9% |
考察
- シャープレシオ(リスク調整後リターン)
TopNが最も高く3.79、続いてWeightedAvgの3.45。MulNormとScoreVolは2.6〜2.8とやや控えめ。
→ 上位スコアのファクターに絞り込むTopN戦略が、効率的なリスク配分を実現している可能性が高いです。
- 最大ドローダウン
TopNが最小の約 -12%、最も良好なリスク管理を実現。WeightedAvgも約 -14% と安定。MulNormとScoreVolはやや大きめのドローダウン。
→ 上位ファクター選択や平均化でリスクを抑えることができています。
- 勝率(トレード成功率)
- どの戦略も約59〜61%の範囲で似通っている。
WeightedAvgがやや高めの61.5%。
→ 勝率は大きな差がなく、リスク・リターンの組み合わせがパフォーマンスの違いに影響していると考えられます。
- ターンオーバー(売買頻度)
ScoreVolとMulNormは70%超えの高い回転率。-
WeightedAvgとTopNは40%前後と比較的低め。
→ 高頻度売買は手数料コストや実行面の課題になりやすく、安定した戦略としては低めのターンオーバーが望ましいです。 -
TopN戦略はシャープレシオが最も高く、ドローダウンも最小。
投資資金を絞って集中投資することで、効率的なリスク・リターンを両立しています。
ターンオーバーも中程度で実運用でも扱いやすいレベル。 -
WeightedAvgは次点で安定感があり、勝率も高い。
リスクパリティとモメンタムをバランス良く加重平均し、リスク管理とパフォーマンスの両立に優れています。
取引回数が少なめなのもプラス要素。 -
MulNormとScoreVolはターンオーバーが高く、手数料コスト面で不利な可能性。
パフォーマンス面でも中庸ですが、ボラティリティ調整など工夫の余地がありそうです。
TopNがよかったですが、RP戦略そのもののr/rは3.7程度なので、モメンタムを組み合わせないほうがよさそうでした…
1か月モメンタムとの合成ならR/Rは向上しそうです
1か月モメンタムの場合
# 共通のRP/Momentum戦略を一度だけ作成して使い回す
rp = risk.RiskParityStrategyScipy(index_data)
rp.calculate_returns()
mom = MomentumStrategy(index_data, window=1)
mom.calculate_returns()
eq_strategy = basestrategy.EqualWeightStrategy(index_data, strategy_name='eq')
eq_strategy.calculate_returns()
import numpy as np
strategies = {
"MulNorm": CombinedStrategyMulNorm(index_data, rp, mom, strategy_name="mulnorm"),
"WeightedAvg": CombinedStrategyWeightedAvg(index_data, rp, mom, strategy_name="wavg"),
"TopN": CombinedStrategyTopN(index_data, rp, mom, top_n=3, strategy_name="topn"),
"ScoreVol": CombinedStrategyScoreVol(index_data, rp, mom, strategy_name="scorevol"),
"RP":rp_strategy,
"Equal Weight":eq_strategy
}
results = []
for name, strat in strategies.items():
stat = strat.evaluate()
stat["strategy"] = name
results.append(stat)
comparison_df = pd.DataFrame(results).set_index("strategy")
comparison_df
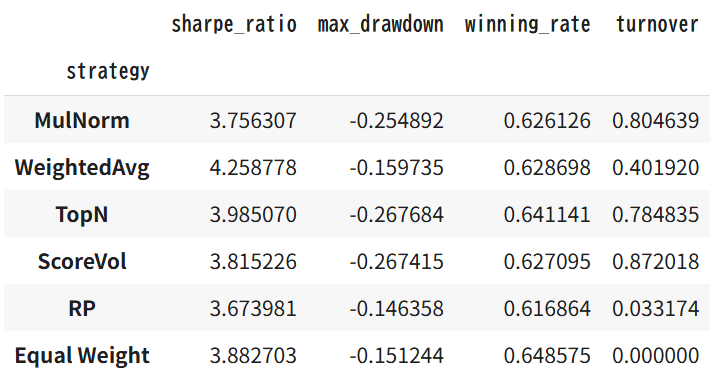
単純なウェイト合成であればR/Rは高かったですが、他の合成方法は微妙です
まとめ
本記事では、リスクパリティとファクターモメンタムの組み合わせによる4種類の合成戦略をPythonで実装・比較しました。
- 構成を外から渡すことで、柔軟に比較が可能
- 戦略間のパフォーマンス差を定量的に評価できる
- モデル拡張も容易(例:QualityやValueファクターの追加)
発展的なアイデア
- ファクター選定の動的切り替え(Adaptive TopN)
- 各戦略をEnsembleして最終ポートフォリオを生成
- 時系列CVによるバックテスト精度の向上
本記事で紹介したコードはこちら

