
今回は Google CloudのCloud Functionsを使って、EDINETから取得した財務データを Google ドライブ 上に定期実行で保存していくコードを作成したいと思います。EDINETからDBを作る部分は以前紹介した記事を参照してください。
これができれば自分で毎回実行しなくても、自動でEDINETの財務諸表データを蓄積していくことができます。
Google Cloudのプロジェクトを作成済みである前提で進めていくので、まだ Google Cloudのプロジェクトを作成していない場合や、Google ドライブの API を使っていない場合には、以前の GoogleドライブAPIを使う方法の記事を確認してください。
Cloud Functionsの作成
まずは関数を作成していきます。
プロジェクトのトップページで、Cloud Functionsを検索します。

ファンクションを作成から、作成を行います。

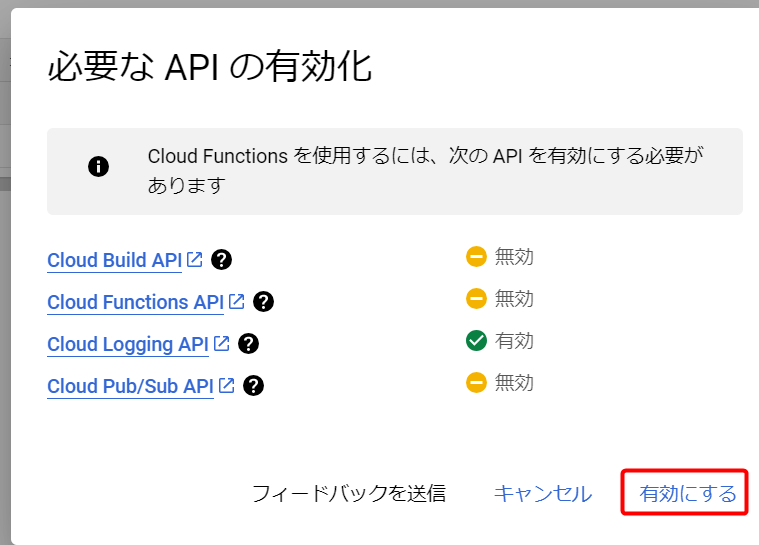
必要な API を有効化するように表示されるので有効にします。
まずは構成部分に関してです。関数名やリージョンは適宜設定してください。トリガータイプは今回は、Pub/Subにしています。トピック ID は任意の ID を入力し 登録しておいてください。

ランタイムの環境設定にいくつか環境変数を入力します。

– EDINET_API:EDINETから取得する API です
– folder_id : ダウンロードしたデータを保存していくGoogleDriveフォルダーのfolder_idです。
– main_folder_id:folder_idの中にmainという別のフォルダを作成して、その下に詳細のデータを保存していていくので、folder_idのフォルダの中にもう一つフォルダを作成して、そのフォルダのidを取得します
フォルダ ID 周りのことがよくわからない場合には Google ドライブ API の使い方を紹介した 別記事をご参照ください。
続いてコード部分の設定になります。
ランタイムは Python を選択します。
エントリーポイントは変更しても良いですか今回はこのままにしています。

コードのmain.pyに以下を記述します。
#Google Cloud
import base64
import functions_framework
import io
import csv
import json
import pandas as pd
from google.oauth2 import service_account
from googleapiclient.discovery import build
from googleapiclient.http import MediaFileUpload, MediaIoBaseDownload
import os
import json
import requests
import pandas as pd
import datetime
import zipfile
import time
import pickle
from collections import defaultdict
from google.oauth2 import service_account
from googleapiclient.discovery import build
from arelle import Cntlr, ViewFileFactTable, ModelDtsObject, XbrlConst
from arelle.XbrlConst import conceptNameLabelRole, standardLabel, terseLabel, documentationLabel
import shutil
import os
from dateutil.relativedelta import relativedelta
# Google Drive APIの認証情報を設定する
SCOPES = ['https://www.googleapis.com/auth/drive']
SERVICE_ACCOUNT_FILE = 'credentials.json' # サービスアカウントキーのJSONファイルパス
main_folder_id = os.environ.get("main_folder_id ")
folder_id = os.environ.get("folder_id ")
api_key = os.environ.get("EDINET_API")
def authenticate_drive():
creds = service_account.Credentials.from_service_account_file(
SERVICE_ACCOUNT_FILE, scopes=SCOPES)
service = build('drive', 'v3', credentials=creds)
return service
service = authenticate_drive()
def search_folder_in_drive(service, folder_id, folder_name):
# 指定されたフォルダIDの中で指定された名前のフォルダを検索し、存在すればそのIDを返す
response = service.files().list(q=f"'{folder_id}' in parents and name='{folder_name}' and mimeType='application/vnd.google-apps.folder'",
spaces='drive',
fields='files(id)').execute()
files = response.get('files', [])
if files:
return files[0]['id']
else:
return create_folder_in_drive(service, folder_name, parent_folder_id=folder_id)
def create_folder_in_drive(service, folder_name, parent_folder_id=None):
# 指定された名前の新しいフォルダを作成し、作成したフォルダのIDを返す
file_metadata = {
'name': folder_name,
'mimeType': 'application/vnd.google-apps.folder'
}
if parent_folder_id:
file_metadata['parents'] = [parent_folder_id]
folder = service.files().create(body=file_metadata, fields='id').execute()
return folder.get('id')
def download_file_from_drive(service, folder_id, file_name, local_file_path):
# Google Driveから指定されたフォルダのCSVファイルをダウンロードする
results = service.files().list(q=f"name='{file_name}' and '{folder_id}' in parents",
spaces='drive',
fields='files(id)').execute()
file_id = results.get('files', [])[0].get('id')
request = service.files().get_media(fileId=file_id)
fh = io.FileIO(local_file_path, mode='wb')
downloader = MediaIoBaseDownload(fh, request)
done = False
while done is False:
status, done = downloader.next_chunk()
def search_file(service, folder_id, file_name):
results = service.files().list(q=f"name='{file_name}' and '{folder_id}' in parents",
spaces='drive',
fields='files(id)').execute()
files = results.get('files', [])
return files
def update_data(service, folder_id, file_name, data_row=None):
# Google Driveに指定されたフォルダのCSVファイルにデータを追記する
# Google Driveに同名のファイルが存在するかチェック
results = service.files().list(q=f"name='{file_name}' and '{folder_id}' in parents",
spaces='drive',
fields='files(id)').execute()
files = results.get('files', [])
if files:
if data_row is not None:
# 既存のファイルがある場合は、その内容を取得して追記する
if os.path.exists(file_name)==False:
download_file_from_drive(service, folder_id, file_name, file_name)
data_row.to_csv(file_name,mode='a',header=False,index=False)
media_body = MediaFileUpload(file_name,
mimetype='text/csv',
resumable=True)
request = service.files().update(fileId=files[0]['id'],
media_body=media_body)
request.execute()
else:
# 新規作成
if data_row is not None:
data_row.to_csv(file_name,index=False)
file_metadata = {
'name': file_name,
'parents': [folder_id]
}
media = MediaFileUpload(file_name,
mimetype='text/csv',
resumable=True)
file = service.files().create(body=file_metadata,
media_body=media,
fields='id').execute()
return file.get('id')
def make_day_list(start_date, end_date):
# 開始日から終了日までの日数を計算
period = (end_date - start_date).days
# 開始日から終了日までの日付リストを生成して返す
day_list = [start_date + datetime.timedelta(days=d) for d in range(period + 1)]
return day_list
# EDINETから企業情報を取得する関数
def make_doc_id_list(day_list):
# 企業情報を格納するリスト
securities_report_data = []
# 各日付についてEDINET APIからデータを取得
for day in day_list:
url = "https://disclosure.edinet-fsa.go.jp/api/v2/documents.json"
params = {"date": day, "type": 2,"Subscription-Key":api_key}
res = requests.get(url, params=params)
json_data = res.json()
# 取得したデータから特定の条件を満たすものを抽出し、リストに追加
for result in json_data["results"]:
ordinance_code = result["ordinanceCode"]
form_code = result["formCode"]
if ordinance_code == "010" and form_code == "030000":
securities_report_data.append(result)
time.sleep(1)
# 抽出した企業情報のリストを返す
return securities_report_data
def download_zip_file(doc_id):
url = f"https://disclosure.edinet-fsa.go.jp/api/v2/documents/{doc_id}"
params = {"type": 1,"Subscription-Key":api_key}
filename = f"{doc_id}.zip"
# 解凍先のディレクトリのパス
extract_dir = filename.replace('.zip','')
res = requests.get(url, params=params, stream=True)
if res.status_code == 200:
with open(filename, 'wb') as file:
for chunk in res.iter_content(chunk_size=1024):
file.write(chunk)
# print(f"ZIP ファイル {filename} のダウンロードが完了しました。")
# ZipFileオブジェクトを作成
zip_obj = zipfile.ZipFile(filename, 'r')
# 解凍先ディレクトリを作成(存在しない場合)
if not os.path.exists(extract_dir):
os.makedirs(extract_dir)
# 全てのファイルを解凍
zip_obj.extractall(extract_dir)
# ZipFileオブジェクトをクローズ
zip_obj.close()
# print(f"ZIP ファイル {filename} を解凍しました。")
else:
print("ZIP ファイルのダウンロードに失敗しました。")
def del_files(doc_id):
# フォルダの削除
folder_name = doc_id
shutil.rmtree(folder_name)
# ファイルの削除
file_name = f"{doc_id}.zip"
os.remove(file_name)
# フォルダが存在するか確認
if os.path.exists(doc_id):
# フォルダごと削除
shutil.rmtree(doc_id)
from arelle.XbrlConst import conceptNameLabelRole, standardLabel, terseLabel, documentationLabel
class MyViewFacts(ViewFileFactTable.ViewFacts):
def __init__(self, modelXbrl, outfile, arcrole, linkrole, linkqname, arcqname, ignoreDims, showDimDefaults, labelrole, lang, cols,col_num=1,label_cell=None):
super().__init__(modelXbrl, outfile, arcrole, linkrole, linkqname, arcqname, ignoreDims, showDimDefaults, labelrole, lang, cols)
self.data = []
def viewConcept(self, concept, modelObject, labelPrefix, preferredLabel, n, relationshipSet, visited):
# bad relationship could identify non-concept or be None
if (not isinstance(concept, ModelDtsObject.ModelConcept) or
concept.substitutionGroupQname == XbrlConst.qnXbrldtDimensionItem):
return
cols = ['' for i in range(self.numCols)]
i = 0
for col in self.cols:
if col == "Facts":
self.setRowFacts(cols,concept,preferredLabel)
i = self.numCols - (len(self.cols) - i - 1) # skip to next concept property column
else:
if col in ("Concept", "Label"):
cols[i] = labelPrefix + concept.label(preferredLabel,lang=self.lang,linkroleHint=relationshipSet.linkrole)
i += 1
attr = {"concept": str(concept.qname)}
self.addRow(cols, treeIndent=n,
xmlRowElementName="facts", xmlRowEltAttr=attr, xmlCol0skipElt=True)
self.add_content(concept, modelObject)
if concept not in visited:
visited.add(concept)
for i, modelRel in enumerate(relationshipSet.fromModelObject(concept)):
nestedRelationshipSet = relationshipSet
targetRole = modelRel.targetRole
if self.arcrole in XbrlConst.summationItems:
childPrefix = "({:0g}) ".format(modelRel.weight) # format without .0 on integer weights
elif targetRole is None or len(targetRole) == 0:
targetRole = relationshipSet.linkrole
childPrefix = ""
else:
nestedRelationshipSet = self.modelXbrl.relationshipSet(self.arcrole, targetRole, self.linkqname, self.arcqname)
childPrefix = "(via targetRole) "
toConcept = modelRel.toModelObject
if toConcept in visited:
childPrefix += "(loop)"
labelrole = modelRel.preferredLabel
if not labelrole or self.labelrole == conceptNameLabelRole:
labelrole = self.labelrole
self.viewConcept(toConcept, modelRel, childPrefix, labelrole, n + 1, nestedRelationshipSet, visited)
visited.remove(concept)
def add_content(self, concept, modelObject):
if concept.isNumeric:
label = concept.label(lang='ja')
s_label = concept.label(preferredLabel=standardLabel, lang='ja')
facts = self.conceptFacts[concept.qname]
if isinstance(modelObject, ModelDtsObject.ModelRelationship):
parent_name = modelObject.fromModelObject.qname
parent_label = modelObject.fromModelObject.label(preferredLabel=standardLabel, lang='ja')
else:
parent_name = None
parent_label = None
if isinstance(modelObject, str):
link_def = self.linkRoleDefintions[modelObject]
elif isinstance(modelObject, ModelDtsObject.ModelRelationship):
link_def = self.linkRoleDefintions[modelObject.linkrole]
for f in facts:
if f.unit is not None:
unit = f.unit.value
else:
unit = None
value = f.xValue
context = f.context
self.data.append([concept.qname,concept.typeQname,concept.name, label, s_label, parent_name, parent_label,value, context.startDatetime, context.endDatetime, unit, link_def,context.id])
def viewFacts(modelXbrl, outfile, arcrole=None, linkrole=None, linkqname=None, arcqname=None, ignoreDims=False, showDimDefaults=False, labelrole=None, lang=None, cols=None,col_num=1, label_cell=None):
if not arcrole: arcrole=XbrlConst.parentChild
view = MyViewFacts(modelXbrl, outfile, arcrole, linkrole, linkqname, arcqname, ignoreDims, showDimDefaults, labelrole, lang, cols,col_num, label_cell)
view.view(modelXbrl.modelDocument)
df = pd.DataFrame(view.data, columns=['Name','Type','LocalName','Label','StandardLabel','ParentName','ParentLabel', 'Value','StartDate','EndDate','Unit','LinkDefinition','ContextID'])
view.close()
return pd.DataFrame(df)
def parse_df(df):
if len(df) > 0:
df = df[df['Value'].isnull()==False]
df = df.drop_duplicates(['Name','ContextID','Value'])
return df[['Name','ParentName','StandardLabel','Value','StartDate','EndDate','Unit','ContextID','ParentLabel']]
def make_dict(df, concept_dict=None):
if concept_dict is None:
# defaultdictの初期化
concept_dict = defaultdict(lambda: {'StandardLabel': None, 'ParentName': None, 'ParentLabel':None})
# dfのデータをdefaultdictに登録
for _, row in df.iterrows():
name = str(row['Name'])
concept_dict[name]['StandardLabel'] = row['StandardLabel']
concept_dict[name]['ParentName'] = str(row['ParentName'])
concept_dict[name]['ParentLabel'] = row['ParentLabel']
else:
# dfのデータをチェックして追加
for idx, row in df.iterrows():
name = str(row['Name'])
std_label = row['StandardLabel']
parent_name = str(row['ParentName'])
name_to_check = name
name_conflict = False
if name_to_check in concept_dict:
if (concept_dict[name_to_check]['StandardLabel'] == std_label and
concept_dict[name_to_check]['ParentName'] == parent_name):
# 名前が既に存在し、StandardLabelとParentNameが同じ場合
name_conflict = False
else:
# 名前が既に存在し、StandardLabelまたはParentNameが異なる場合
name_conflict = True
name_to_check = name + '_new'
count = 1
while name_to_check in concept_dict:
if (concept_dict[name_to_check]['StandardLabel'] == std_label and
concept_dict[name_to_check]['ParentName'] == parent_name):
# 名前が既に存在し、StandardLabelとParentNameが同じ場合
name_conflict = False
break
else:
name_to_check = f"{name}_new{count}"
count += 1
if name_conflict:
# 新しい名前を登録
concept_dict[name_to_check]['StandardLabel'] = std_label
concept_dict[name_to_check]['ParentName'] = parent_name
concept_dict[name_to_check]['ParentLabel'] = row['ParentLabel']
df.loc[idx, 'Name'] = name_to_check
else:
# 名前が既に存在し、StandardLabelとParentNameが同じ場合
concept_dict[name]['StandardLabel'] = std_label
concept_dict[name]['ParentName'] = parent_name
concept_dict[name]['ParentLabel'] = row['ParentLabel']
return concept_dict, df
meta_cols = ['date','seqNumber', 'docID', 'edinetCode', 'secCode', 'JCN', 'filerName', 'fundCode', 'ordinanceCode', 'formCode', 'docTypeCode', 'periodStart', 'periodEnd', 'submitDateTime']
def make_metafile(meta_csv_file):
if search_file(service, folder_id, meta_csv_file):
if os.path.exists(meta_csv_file)==False:
download_file_from_drive(service, folder_id, meta_csv_file, meta_csv_file)
df_meta = pd.read_csv(meta_csv_file)
if len(df_meta) > 0:
seq_num = df_meta.iloc[-1,:]['seqNumber']
date_prev = df_meta.iloc[-1,:]['date']
date_prev = datetime.datetime.strptime(date_prev, '%Y-%m-%d')
else:
date_prev = None
seq_num = 0
else:
df_header = pd.DataFrame(columns=meta_cols)
df_header.to_csv(meta_csv_file, index=False)
update_data(service, folder_id, meta_csv_file)
date_prev = None
seq_num = 0
return date_prev, seq_num
concept_file_path = 'concept_dict.pkl'
def load_concept():
if os.path.exists(concept_file_path)==False:
if search_file(service, folder_id, concept_file_path):
download_file_from_drive(service, folder_id, concept_file_path, concept_file_path)
else:
concept_dict = defaultdict(lambda: {'StandardLabel': None, 'ParentName': None, 'ParentLabel':None})
return concept_dict
# ファイルから読み込む
with open(concept_file_path, 'rb') as file:
loaded_normal_dict = pickle.load(file)
# 普通の辞書をdefaultdictに変換
concept_dict = defaultdict(lambda: {'StandardLabel': None, 'ParentName': None, 'ParentLabel':None}, loaded_normal_dict)
return concept_dict
def save_concept(concept_dict):
# # defaultdictを普通の辞書に変換
normal_dict = dict(concept_dict)
with open(concept_file_path, 'wb') as file:
pickle.dump(normal_dict, file)
update_data(service, folder_id, concept_file_path)
header = ['doc_id', 'Name', 'Value', 'StartDate', 'EndDate', 'Unit', 'ContextID']
def main():
concept_dict = load_concept()
# 日付範囲
meta_csv_file = '2024.csv'
date_prev, seq_num = make_metafile(meta_csv_file)
if date_prev is None:
start_date = datetime.date(2024,7,1)
else:
start_date = date_prev.date()
end_date = datetime.datetime.today().date()
# 日付範囲から日付リストを作成する関数を呼び出し
day_list = make_day_list(start_date, end_date)
for date in day_list:
folder_year = date.year
meta_csv_file = f'{folder_year}.csv'
date_prev, seq_num = make_metafile(meta_csv_file)
if date_prev is not None:
if date_prev.date()>date:
continue
year_folder_id = search_folder_in_drive(service, main_folder_id, folder_year)
# 日付リストを利用してEDINETから企業情報を取得する関数を呼び出し
securities_report_data = make_doc_id_list(2026/07/26)
# 取得した企業情報をデータフレームに格納
df = pd.DataFrame(securities_report_data)
print(date,len(df))
if len(df) == 0:
continue
df = df.sort_values('seqNumber')
df_ex = df[(~(df['secCode'].isnull())) & (df['legalStatus']!='0') & (df['xbrlFlag']=='1')]
name = date.strftime('%Y%m%d')
print(date,len(df_ex))
if len(df_ex) > 0:
csv_file = name + '.csv'
counter = 0
for _, row in df_ex.iterrows():
if date_prev is not None:
if date_prev.date()==date and row['seqNumber'] <= seq_num:
continue
doc_id = row['docID']
download_zip_file(doc_id)
file_list = os.listdir(f'{doc_id}/XBRL/PublicDoc')
xbrl_files = [file for file in file_list if file.endswith('.xbrl')]
xbrl_file = os.path.join(f'{doc_id}/XBRL/PublicDoc', xbrl_files[0])
cols = ['Concept','Facts']
ctrl = Cntlr.Cntlr(logFileName='logToPrint')
modelXbrl = ctrl.modelManager.load(xbrl_file)
data = viewFacts(modelXbrl, 'test.csv', cols=cols, lang='ja')
data = parse_df(data)
concept_dict,data = make_dict(data, concept_dict)
data['doc_id'] = doc_id
update_data(service, year_folder_id, csv_file, data[['doc_id','Name','Value','StartDate','EndDate','Unit','ContextID']])
row['date'] = date.strftime('%Y-%m-%d')
add_data = pd.DataFrame(row).T.loc[:,meta_cols]
update_data(service, folder_id, meta_csv_file, add_data)
save_concept(concept_dict)
del_files(doc_id)
counter += 1
print(len(df_ex),counter)
# Triggered from a message on a Cloud Pub/Sub topic.
@functions_framework.cloud_event
def hello_pubsub(cloud_event):
main()
requirements.txtは次のようにします。
functions-framework==3.*
arelle-release
google-auth
google-api-python-client
pandas
requests
datetime
google-cloud-storage
google-cloud-bigquery
zipfile36
また、認証情報を記入したcredentials.jsonというファイルを新しく作成して、中身に認証情報を記入しておきます。
これで準備は完了です。デプロイをして、テスト実行してみて、うまくログが出力されていれば成功です。
取得の開始日などは必要に応じて変更してください。
環境変数がうまく認識されない場合があります。その場合はあまり推奨されませんが行動に直接環境変数の値を入力することで、解決できます。
デプロイを行って、テストを行い、うまく登録されることを確認できたら、定期実行のためのスケジュールを設定していきます。

Cloud Scheduler
定期実行のためには,
Cloud Scheduler APIを使用することができます.
まずはコンソールで検索をし API を有効にします


ジョブを作成から新しいジョブを作成します。

名前やリージョンは自由に設定をします。
今回は毎朝5時に実行するための頻度を入力しました。
「0 5 * * *」で5時に実行することができます
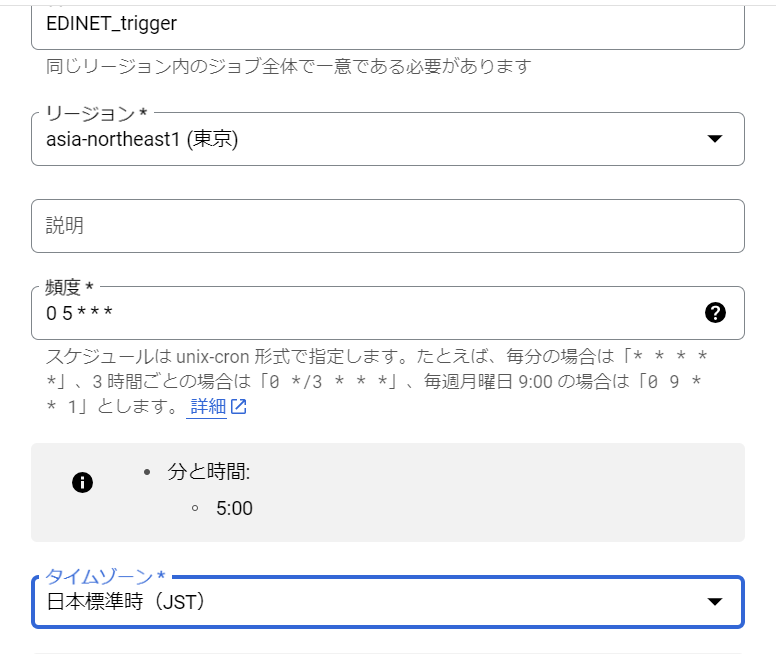
ターゲットタイプは、Pub/Subにして作成したトピックを選択し保存します。
これで定期実行で自動的にデータ収集が可能になります。
時々メモリーサイズが足りないようなのでその場合にはメモリーサイズを大きくするなどして対応してください。

