
今回は、有価証券報告書などのデータが提供されるファイル形式であるXBRLについて紹介していきたいと思います。
XBRLは情報も少なく、しっかりと構造を理解していないと、解析が難しいので、プログラミングなどで扱おうと思ってもなかなかうまくいかない人が多いかと思います。
そこで、今回は少しでもその仕組みをわかりやすく紹介していきたいと思います。
そもそもXBRLとは
XBRL(eXtensible Business Reporting Language)は、企業の財務報告を電子的に行うためのXMLベースの言語です。主に財務データの標準化と自動化を目的とし、投資家や規制当局、会計士など、様々な利害関係者が財務情報を効率的に利用できるようにするために開発されました。
XBRLの基本構造
XBRLファイルを読むためには、まずその構造を理解しておく必要があります。
さまざまな専門用語があり、かなり難しくなるので、少しずつ順を追って説明していきたいと思います。
XBRLファイルを含んだフォルダーやzipをダウンロードすると、その中に複数のファイルが格納されているケースがほとんどです。
ですので、そもそも解析する際にはどのファイルを読み込んでいけばいいのかもまずわからないかと思います。
しかし、基本的に読み込むファイルは.xbrlとなっているファイルだけで十分です。
その中に基本的に解析する内容の情報が含まれています。一緒に格納されているファイルを参照する必要がある場合は、その情報も、このXBRLに全て書いてあります。
一緒に格納されていることが多いixbrlもしくはHTMLがある場合には、これらを開いてみると、実際の情報を人間が理解できる形で生じできるので、ファイルを開いてみましょう。
ixbrlファイルは、インラインXBRLというファイルで、人間も理解できて、かつXBRLの解析もしやすいという一石二鳥の方法として採用されているものです。このファイルはクロームなどのブラウザで表示できるので、どういった内容かを人間が確認するためには最適です。
それでは、XBRLの詳しい構造を見ていきます。
XBRL文書は以下のような要素で構成されています:
- インスタンス文書(Instance Document): 実際の財務データを含むXMLファイルです。
- タクソノミー(Taxonomy): 財務データの項目や構造を定義するファイル群で、スキーマファイル(.xsd)やラベルリンクベース(.xml)などが含まれます。
- リンクベース(Linkbase): 各要素間の関係や追加情報を提供するファイル群です。
インスタンス文書
まずXBRLを読み込むにあたって、その中には様々な要素が含まれています。
基本的な要素に端しては、インスタンス文書に記載されています。例えば、2024年の売上高が10億円といったような情報です。
売上高という項目とそれに対応する数値、その売上高がいつ発表されたものなのか、単位は円なのかドルなのかといったような情報です。
この売上高という一つの項目が要素となっているイメージです。
要素を見分けるためにはqnameと呼ばれる名前のようなものが使用されます。
これは少しややこしい長めのアルファベットが使われています。
なぜ直接日本語の売上高といったような名前が使用されていないのでしょうか。
それは同じ意味の売上高という項目でもこのqnameにはさまざまな種類が存在しているからです。
会計基準の違いであったり、様々な違いによって分類上は異なるため、qnameは違うもののラベルや意味としては同じといったようなケースが多く存在します。これがXBRLファイルの解析を難しくする一つ目の要素です。それらを見分けるために日本語の一般的なラベル(売上高など)ではなく、qnameが用いられます。
もし単純にXBRLファイルに含まれている要素にどんなものがあるのか、一覧を取得したいだけであれば、比較的簡単に行うことができます。
例えば、売上高に対応するqnameさえ分かっていれば、そのqnameの要素を取ってくればいいということになります。
しかし、このqnameは膨大な量があり、自分が知りたい項目がどういったqnameなのかを知るのが大変です。
簡単な方法としては既にエクセルなどに項目一覧としてまとめられているものを使用するという方法はあります。
タクソノミー
各qnameがどういった名前や意味を持っているのか、あるいは他の要素との関係性はどうなっているのかといった情報は、タクソノミと呼ばれます。タクソノミ―では売上高や純資産などの財務データの項目やラベルの情報をまとめています。
このタクソノミファイルを解析することで要素の意味や関係性を知ることができるのですが、単純にqnameとそれに対応するラベルが欲しいだけであれば、多くの場合XBRLを作成するための仕様書にエクセルの形式で提供されていることが多いです。
ですので、まずはこのExcelシートを見てどういった項目があるのかそのqnameが何かそしてqnameの値を取得するという流れをやってみるのがオススメです。
ですがここで問題となってくるのが、このタクソノミが定期的に更新される可能性があり、またファイルごとに参照しているタクソノミは異なっている場合があるので、自分が思ったような要素を取得できないということです。また先程も説明したように、同じ売上高という項目を欲しいと思った時には、それに対応するqnameが複数あるため、様々なqnameをキーとしてファイルから要素を探し出す必要があるのが問題点です。
これを解決するためには、XBRLを読み込んでそのXBRLがどのタクソノミを使っているか知る必要があるということです。
そのためにはスキーマリンクというリンク先を読み込む必要があります。
このスキーマリンクはスキーマファイルに格納されておりX xsd形式のファイルパスが記入されたリンクになります。
このファイルは多くの場合、XBRLが格納されているディレクトリーにそのまま置いてあります。
そして、そのファイルの中身にどのようなタクソノミを使っているのかという項目が書かれているのです。
そこに書かれているタクソノミファイルをダウンロードして使用する必要があります。
このタクソノミファイルをダウンロードすれば、XBRLファイルに含まれているすべての要素を順番に確認していき、そのqnameに対応するラベルを取得することができます。
XBRLの内部に含まれる要素について詳しい情報が書かれているのがタクソノミというものですが、これには大きく分けて2種類存在します。
まず一つが、EDINETやTDNetといったところから提供されている共通するタクソノミです。一方で、個別のXBRL作成者から提供されるタクソノミも存在します。
基本的には共通部分を読み込んで、使えばいいのですが、独自の項目を作りたいといった場合には別途定義を知っているため、そのファイルが一緒に含まれています。
例えば、セグメントや取締役の名前、といったような項目は、共通要素には含まれないので、独自に定義されている場合が多いです。また、その他についても、いくつかのファイルについては提供者自身で提供するように求められているなど提出方式によって様々なルールが存在しています。
ですが、それらも基本的にXBRLファイルの中にどのファイルを参照すればいいかということが書いてあるので、それをしっかりと理解していれば追うことが可能です。これらのファイルを全て解析できるようになると、何が嬉しいのかというと、単純に要素の対応付けを知る以外の関係性情報を知ることができるからです。これがリンクベースの情報になります。
リンクベース
関係性情報の中でも重要な情報は大きく二つあります。一つ目がそれぞれの要素の親子関係を知ることができるということです。
この親子関係というのは例えば、資産という項目には流動資産と固定資産という項目があるといったような関係を取得できるということです。
もちろん決まった数の要素であれば要素間の関係を自分で定義して準備してあげても良いかもしれません。
しかし、先程から説明しているようにかなりの数の要素数があり、それらは複雑な関係性を持っています。自分でいちいちマッピングをしていてはなかなか骨の折れる作業となってしまいますので、そこでXBRLを解析することで、こういった情報を取得できます。しかしこういった情報はExcelには反映されていないので、独自でXBRLを解析する必要があります。
二つ目の大きな利点は計算関係を得ることができるということです。財務諸表の1部の要素には計算関係という関係が存在します。これは先程の資産の例ですと、資産という項目は流動資産と固定資産という二つの項目の足し算で成立しているといったような関係になります。他の項目では引き算という場合もあるので、そういった関係性やどの項目を組み合わせるとどの項目になるのかといった情報を取得できます。これは計算関係リンクと呼ばれるリンクに定義されています。
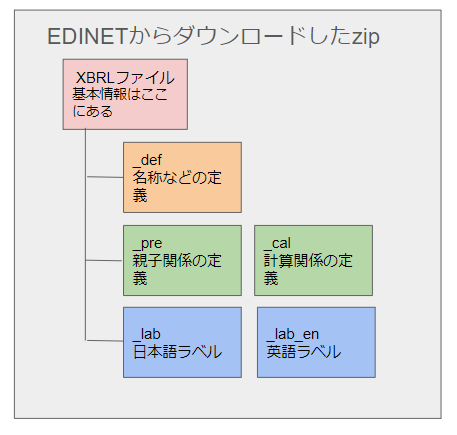
EDINETの場合の主なファイル構成
ここで少し各ファイルとそれぞれの機能の対応を整理しておきます。
まずは_defとなっているファイルです。こちらは定義ファイルとなっており名称や使われている名前の定義がされています。
続いて_lab_となっているファイルです。こちらはqnameに対する日本語ラベルが記入されています。ある意味、項目の意味を説明していると捉えることができます。
また_lab_enとなっているファイルは英語版のラベルを示すファイルになっています。また、このラベルファイルにはローカルラベルとスタンダードラベルという2種類が存在しています。
ローカルラベルというのは提供者自身が定義していたりする名前となっていたり、このスタイルでだけ通用する名前といったようなケースが多いですが、スタンダードラベルは他の形式で書かれていた場合にも使えたりするように、ある種の正規化処理がされているので、複数の会計方式を横比較したいといったような場合にはスタンダードラベルを使用します。
続いて親子関係を示すファイルは_preファイルです。また、_cal_となっているファイルは計算関係を示すファイルになっています。このように様々な情報が、それぞれのファイルに格納されているので、必要に応じてそういったファイルを解析していく必要があります。
インラインXBRLとXBRLの関係
EDINETの場合はインラインXBRLとXBRLの二つが提供されていますが、TDNetはインラインXBRLしか提供されていないため、インラインXBRLとXBRLの関係性を理解しておくことは分析において非常に重要です。
EDINETでは会社側がインラインXBRLを作成しそれをEDINETに提出します。そして、EDINETがそのインラインXBRLを解析してXBRLを作成しています。もし自分で全ての情報を解析したい場合は大きく二つの方法があります。
一つ目は直接インラインXBRLを解析してそこから情報を抽出するという方法です。
もう一つはインラインXBRLをXBRLに変換するプログラムを作ってXBRLを解析するという二段階の方法です。
一見後者のほうが面倒くさいようなイメージを持つかもしれませんが、XBRLファイルがしっかりと出来ていればそれを解析するのは比較的ライブラリーなどの環境が整っています。
一方で、インラインXBRLは少なくともEDINETやTDNetで提供されているものはXBRL解析で使用されているライブラリーでは一部がうまく機能しません。
さらに詳しく理解するには
さらにXBRLの構造やEDINETのファイル構造を知るためには、以下のEDINETトップページにあるの操作ガイドがおすすめです。

クリックすると

このような一覧が表示されます。
この中の
– EDINETタクソノミの概要説明
– 提出者別タクソノミ作成ガイドライン
– 報告書インスタンス作成ガイドライン
などの内容を確認するとより理解が深まると思います。
まとめ
今回は、有価証券報告書の形式であるXBRLファイルの構造について紹介しました。
かなり複雑ですが、これを解析できるようになると非常に多くの情報を得ることができます。
次回は、実際にXBRLを解析するには、どのようにすればいいかPythonを使いながら見ていきます。

