
EDINETは有価証券報告書などを管理しているサイトで、日本企業の提出された有価証券報告書を閲覧、ダウンロードできます。
APIも公開されているので、APIを使うことで、無料ですべての企業の有価証券報告書を取得できます。
難点としては、XBRLという特殊な形式のファイルで出力されるデータがあるので、それらの扱い方を知る学習コストが高いということかと思います。
今回は、このEDINET APIを使ったデータ取得の方法を紹介していきます。
EDINETの扱い方を習得すれば、必要なデータを抽出して、ChatGPTと組み合わせて、分析するアプリなども作成できます。
興味のある方はこちらの記事をご覧ください。
EDINET APIの取得方法
EDINET APIが2023年8月21日から変更となり、アカウントの登録とAPIキーの取得が必要となりました。
アカウントの作成はこちらのドキュメント一覧の
『EDINET API仕様書(Version 2)』の「2章 APIの利用準備」に記載されていますので、基本的にはこの手順に従うことで作成可能です。
以前はMicrosoft Edgeのみ対応していましたが、現在はChromeにも対応しているようです。
登録やログインは以下のサイトから行えます。

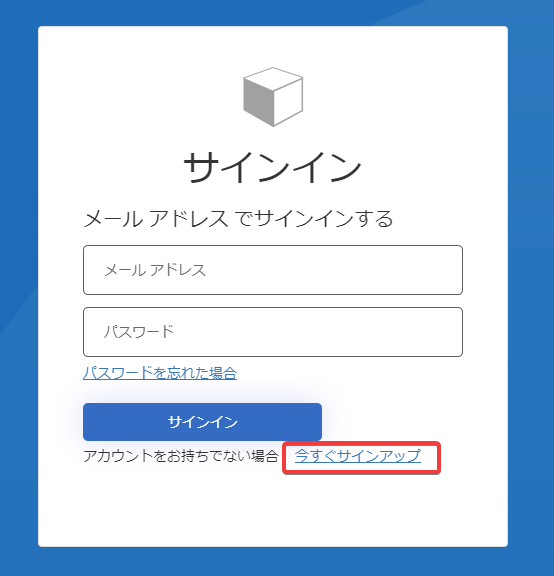
まずは、今すぐサインアップから登録を進めます。
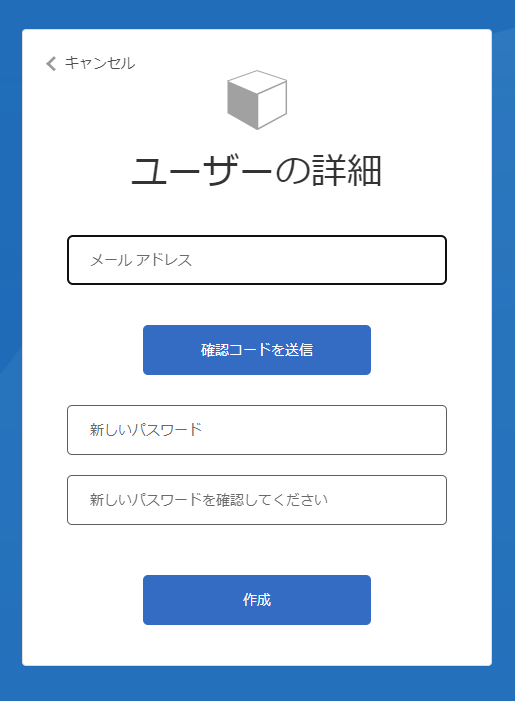
ユーザー情報を入力します。
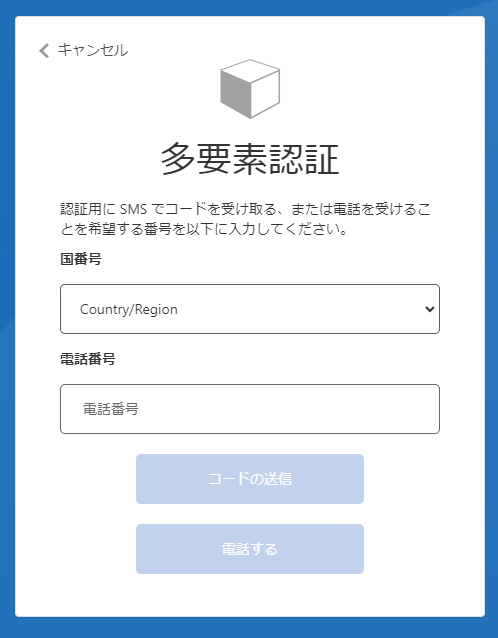
認証の情報を入力します。

多要素認証でのサインイン後に表示されるAPI キー発行画面で連絡先を登録することによりEDINET API の利用に必要となるAPI キーが表示されます。画面に表示されるAPI キーはリクエストパラメータとして使用するため、忘れずに保存してください。
APIを使ったデータ取得
DINETのAPIは大きく二つのデータを取得することができます。
一つ目は特定の日に公開された、有価証券報告書をはじめとする、開示資料の一覧を取得できるAPIです。
このAPIを使うことで、いつどのような資料が公開されたのか知ることができます。
そしてこのデータの中にはそれぞれの開示資料を区別するためのコードが含まれており、このコードを使うことで特定の資料をダウンロードできるようになります。
特定の企業の開示資料を取得するためには、まず初めに、開示資料一覧を取得するAPIを使ってどういった開示資料が公開されているのか、その開示資料に対応するコードが何なのかを取得します。
開示資料の一覧は、会社名などを検索することによって取得できるような形式ではなく、特定の日付に公開された一覧を取得することしかできないため、今回は開始日と終了日を入力し、その期間に公開された開示資料の一覧を取得するという方法を取ります。
まずは、指定期間に公開された文書の一覧を取得します。
# 指定した日付範囲内の日付リストを生成する関数
def make_day_list(start_date, end_date):
# 開始日から終了日までの日数を計算
period = (end_date - start_date).days
if period > 60:
# 期間が60日を超える場合はエラーメッセージを表示してNoneを返す
print("期間は60日以内にしてください。")
return None
# 開始日から終了日までの日付リストを生成して返す
day_list = [start_date + datetime.timedelta(days=d) for d in range(period + 1)]
return day_list
# EDINETから企業情報を取得する関数
def make_doc_id_list(day_list):
# 企業情報を格納するリスト
securities_report_data = []
# 各日付についてEDINET APIからデータを取得
for day in day_list:
url = "https://disclosure.edinet-fsa.go.jp/api/v2/documents.json"
params = {"date": day, "type": 2,"Subscription-Key":api_key}
res = requests.get(url, params=params)
json_data = res.json()
# 取得したデータから特定の条件を満たすものを抽出し、リストに追加
for result in json_data["results"]:
ordinance_code = result["ordinanceCode"]
form_code = result["formCode"]
if ordinance_code == "010" and form_code == "030000":
securities_report_data.append(result)
time.sleep(1)
# 抽出した企業情報のリストを返す
return securities_report_data
# 企業一覧を取得し、日付範囲内のデータをデータフレームに格納する
# 日付範囲
end_date = datetime.date.today()
start_date = end_date - datetime.timedelta(days=10)
# 日付範囲から日付リストを作成する関数を呼び出し
day_list = make_day_list(start_date, end_date)
# 日付リストが有効な場合
if day_list is not None:
# 日付リストを利用してEDINETから企業情報を取得する関数を呼び出し
securities_report_data = make_doc_id_list(day_list)
# 取得した企業情報をデータフレームに格納
df = pd.DataFrame(securities_report_data)
# カラム名を変更して整理
columns = {
"filerName": "企業名_raw",
"edinetCode": "EDINETコード",
"secCode": "銘柄コード5桁",
"docDescription": "報告書の種類"
}
df = df.rename(columns=columns)
# 銘柄コードを整形して別のカラムとして追加
df['銘柄コード'] = df['銘柄コード5桁'].astype(str).str[:4]
# 企業名に含まれる全角文字を半角文字に正規化して整形
df["企業名"] = df["企業名_raw"].apply(lambda x: unicodedata.normalize('NFKC', x))
df
実行すると、start_dateからend_dateの期間に公開された報告書の一覧を取得できます。
この中にdocIDという項目があるので、そのdocIDを指定することで、公開された報告書の本体を取得できます。
今回は、dfの1行目の報告書を取得したいと思います。
def download_zip_file(doc_id):
url = f"https://disclosure.edinet-fsa.go.jp/api/v2/documents/{doc_id}"
params = {"type": 1,"Subscription-Key":api_key}
filename = f"{doc_id}.zip"
# 解凍先のディレクトリのパス
extract_dir = filename.replace('.zip','')
res = requests.get(url, params=params, stream=True)
if res.status_code == 200:
with open(filename, 'wb') as file:
for chunk in res.iter_content(chunk_size=1024):
file.write(chunk)
print(f"ZIP ファイル {filename} のダウンロードが完了しました。")
# ZipFileオブジェクトを作成
zip_obj = zipfile.ZipFile(filename, 'r')
# 解凍先ディレクトリを作成(存在しない場合)
if not os.path.exists(extract_dir):
os.makedirs(extract_dir)
# 全てのファイルを解凍
zip_obj.extractall(extract_dir)
# ZipFileオブジェクトをクローズ
zip_obj.close()
print(f"ZIP ファイル {filename} を解凍しました。")
else:
print("ZIP ファイルのダウンロードに失敗しました。")
doc_id = df.iloc[0,:]['docID']
download_zip_file(doc_id)
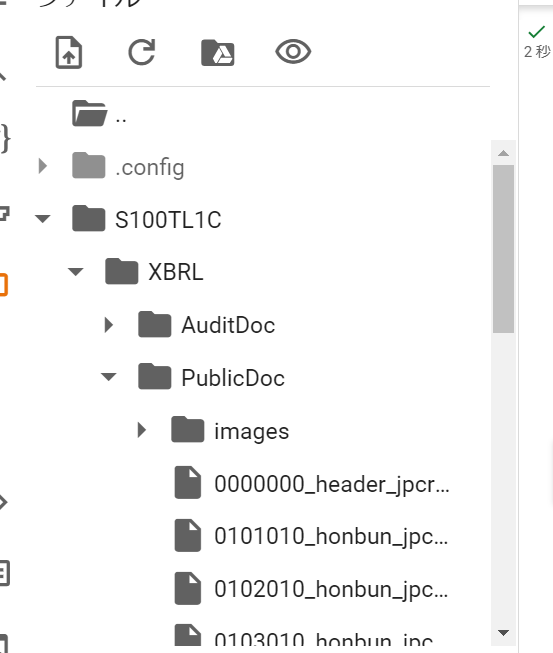
関数を実行すると、画像のように、ZPIファイルがダウンロードされ、解凍された状態になります。
今回は、EDINET APIを使って、有価証券報告書をダウンロードする方法を紹介しました。
これで有価証券報告書のファイル一式は手に入りましたが、これだけでは正直何を見ていいのかわからないと思います。
次回は、この解凍したファイルからデータを取り出す方法を紹介していきます。

